Web::PageMeta - get page open-graph / meta data
a mixed sync/async lazy Perl Moose HTTP-GET module
Some time ago I've wrote Web::PageMeta which had the initial goal to be able to return web page title, description and image as defined by Open-Graph standard. This is information that most link-sharing platforms, like social-networks or messaging services, use when you post a link.
for example:
$ perl -Ilib -MDDP -MWeb::PageMeta -C7 -E 'p(Web::PageMeta->new(url => "https://blog.kutej.net/2021/09/efeu")->page_meta)'
{
description "Experiment → can I grow ivy on fence and gate?",
image "https://blog.kutej.net/2021/09/efeu/thumbnail.jpg",
title "Ivy green gate",
type "website",
url "https://blog.kutej.net/2021/09/efeu"
}
Thanks to Open-Graph tags, posting these blog links results in:

(FB)

(Whatsapp)
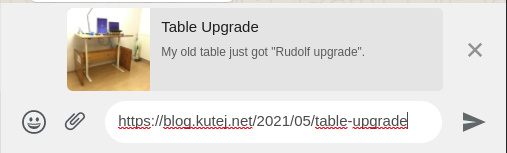
(Whatsapp Web)
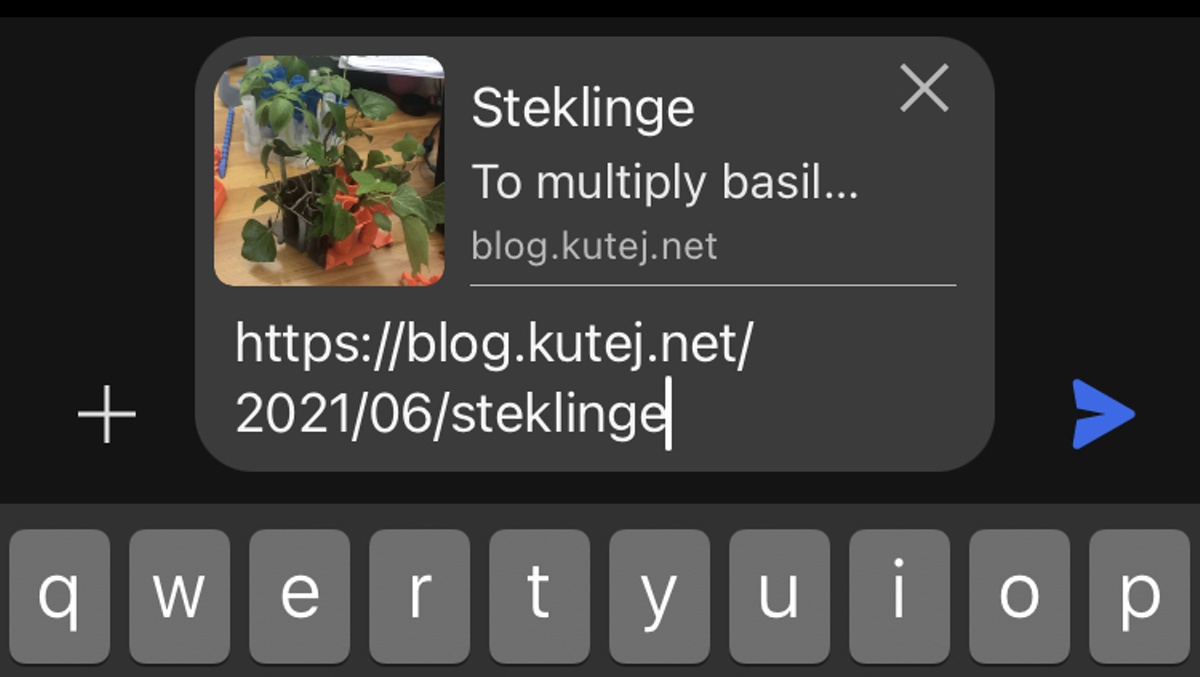
(Signal)

(Telegram Web)
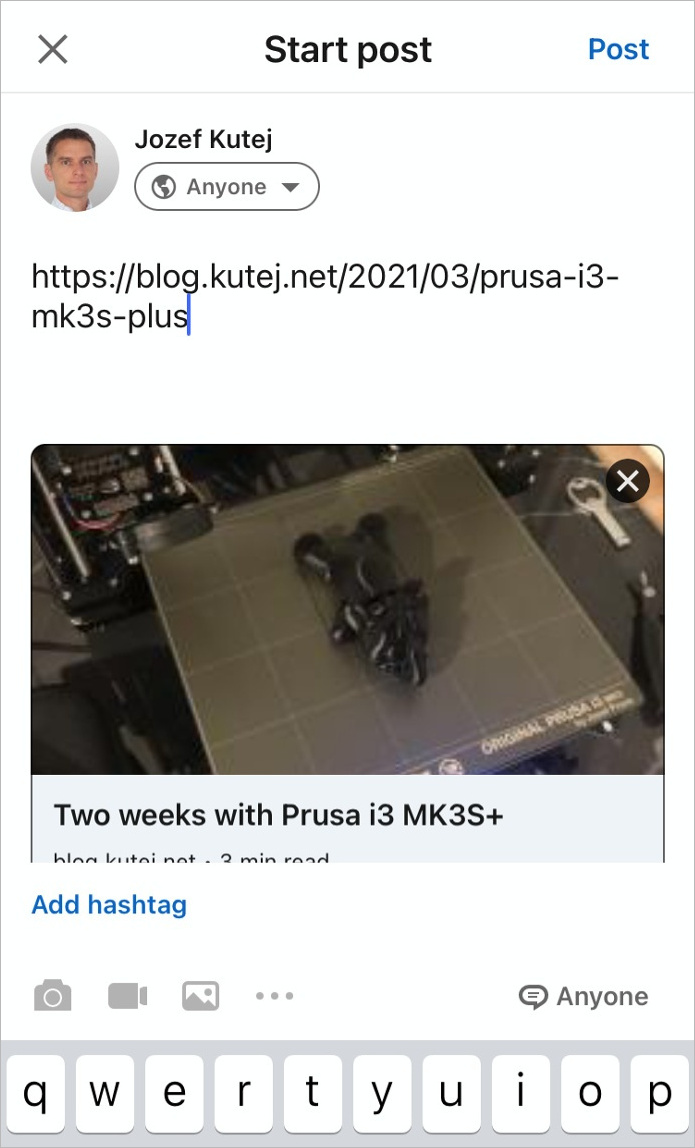
(Linkedin)
Web::PageMeta is basically normal HTTP GET&parse module. What makes it different is that it can work well with both sync and async code. Using Moose lazy builders class is constructed with URL and data are made ready when needed via accessors:
use Web::PageMeta; my $page = Web::PageMeta->new(url => "https://www.meon.eu/"); say $page->title; say $page->description; say $page->image;
results in:
Ivy green gate Experiment → can I grow ivy on fence and gate? https://blog.kutej.net/2021/09/efeu/thumbnail.jpg
For async code there are Future methods to wait for (fetch_page_meta_ft and fetch_image_data_ft) depending if only content information is needed or also the image data. Thanks to Future::AsyncAwait there are not too many callbacks. Using Web::Scraper::LibXML additional information can be extracted from the websites that does not include Open-Graph markup.
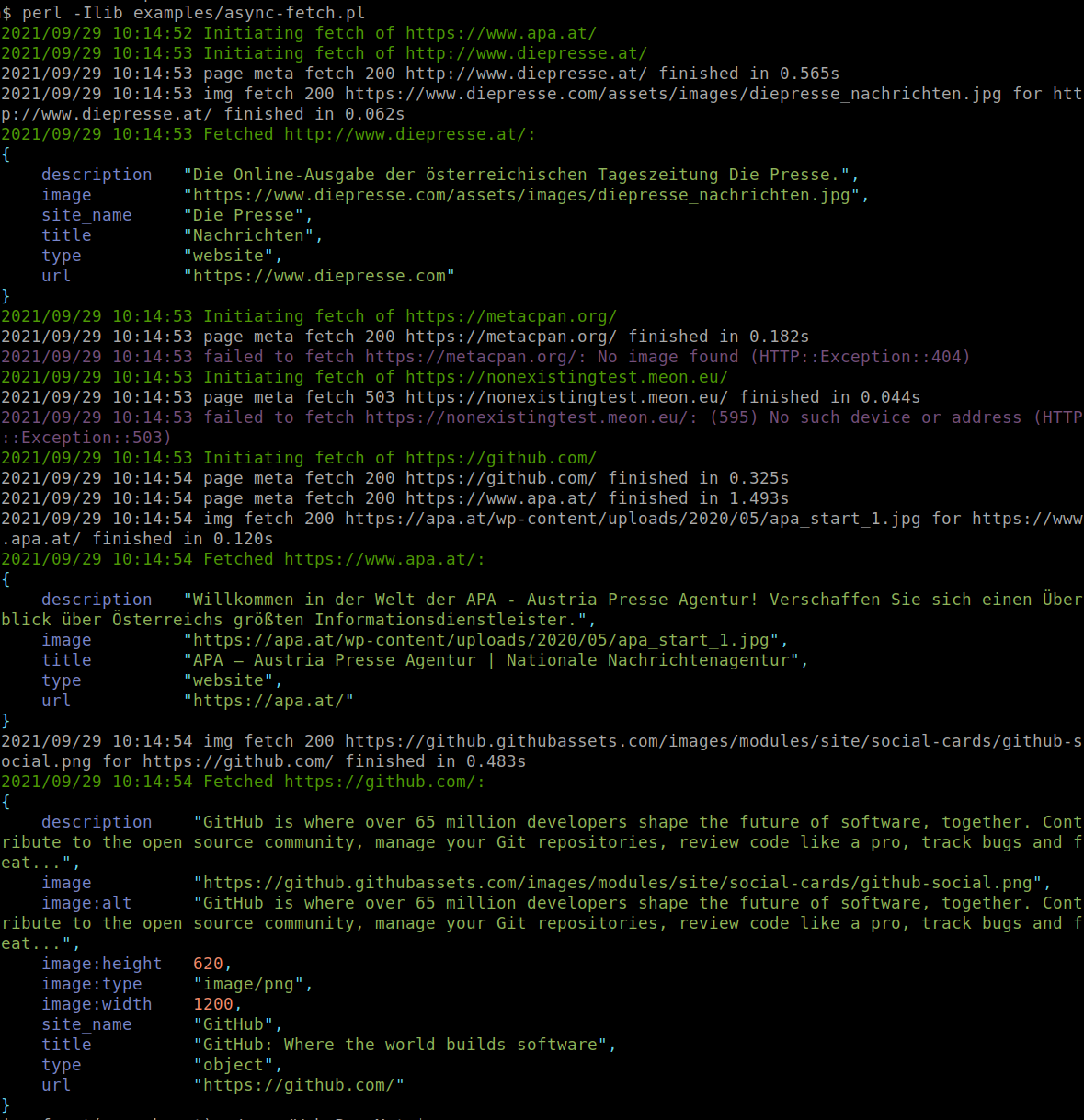
Here is an async example fetching page meta information with concurrency of 2:
and the output: